Every product team has more feature requests than it can build. The hard part is not collecting them. The hard part is deciding which ones matter, in what order, and being able to explain why. Most teams default to whoever argues loudest or whichever request arrived most recently. There is a better way.
This guide walks through a complete, repeatable process: how to gather the right signal, why raw vote counts mislead, how to apply scoring frameworks like RICE and MoSCoW, how to weight requests by customer value and revenue, and how to turn a ranked list into an actual roadmap.
Prioritizing feature requests well means scoring each request on a consistent set of inputs — demand, customer value, effort, and strategy fit — rather than reacting to raw volume or the loudest complaints. Gather signal from votes and comments, weight it by revenue and segment, score with a framework like RICE or MoSCoW, plot value against effort, then sequence the survivors into a roadmap.
Why raw vote counts mislead
Vote counts are the most visible signal on any feedback board, which is exactly why they are dangerous to use alone. A high vote count tells you a request is popular. It does not tell you whether the people voting matter to your business, whether the request aligns with where the product is going, or whether building it would move a metric you care about.
Three failure modes show up repeatedly:
The loud minority. Twenty engaged users who check your board weekly can out-vote a silent majority who never visit it. The request with the most votes is often the one your most online users want, not the one your most valuable customers need.
Survivorship bias. Only users who are still around vote. The customers who churned because a critical capability was missing never registered an opinion. Their absence skews the board toward incremental polish for existing users and away from the gaps that cost you new revenue.
Equal weighting. A free-tier hobbyist and an enterprise account on a six-figure contract each cast one vote. If those votes count the same, your prioritization optimizes for headcount, not value.
Vote counts are a useful starting input. They are a terrible final answer. The rest of this guide is about turning that raw signal into a defensible ranking.
Gather the right signal
Before you score anything, collect the inputs that actually predict good prioritization decisions. Four signals do most of the work.
Demand. How many people want this, and how often are they asking? Vote counts on your feedback board are the headline number, but request frequency over time matters as much. A feature that gains ten new votes every week for six months has sustained demand. A feature that spiked to 100 votes once and went quiet may be less urgent than the raw total suggests.
Customer value. Who is asking? A request from fifty enterprise accounts on annual contracts can outweigh three hundred requests from free-tier users, depending on your business model. Tie requests to revenue, plan tier, and account health wherever you can.
Effort. What will it cost to build, in total — design, engineering, QA, documentation, and launch — not just backend code. Get this estimate from the people who will do the work, not from the person excited to ship it.
Strategy fit. Does this support where the product is going? A request with five hundred votes that pulls against your current direction should score lower than its popularity implies. A request that advances your roadmap goals can earn priority even with modest demand.
The qualitative layer matters too. Vote counts tell you how many. User comments tell you why. "I have to export to a spreadsheet and reformat it manually every week" is a different level of value than "it would be nice if the colors matched our brand." Read the comments before you score.
Apply a scoring framework
Once you have signal, a framework turns it into a comparable ranking. No single framework is correct for every situation — they answer different questions. Here is when to reach for each.
RICE: score the full backlog
The RICE framework was developed by Intercom's product team. It scores each request on four factors and produces a single number you sort by:
RICE Score = (Reach × Impact × Confidence) ÷ Effort
Reach is how many users a request affects in a given period. Impact is how much it moves the needle for each one, on a coarse scale. Confidence discounts the score when you are guessing rather than working from data. Effort is total person-months. RICE shines when you need a defensible numeric ranking across a large, mixed backlog and you have enough data to estimate the inputs. The RICE scoring calculator runs the math for you during planning. For the full method, scales, and a worked example, see the complete RICE guide.
MoSCoW: scope a release
MoSCoW prioritization sorts requests into four buckets: Must have, Should have, Could have, and Won't have. It was created by Dai Clegg at Oracle in 1994 and later formalized in the DSDM agile framework. MoSCoW is a scoping tool, not a ranking tool. It answers "what goes into this release?" rather than "in what order do we build it?" Its most valuable category is the one teams skip: an explicit Won't-have list prevents scope creep and sets expectations with stakeholders. Use MoSCoW to agree on scope, then use RICE to sequence within it.
Kano: understand how requests affect satisfaction
The Kano model classifies features by how they affect customer satisfaction: basic expectations whose absence causes dissatisfaction, performance features where more is better, and delighters that produce outsized satisfaction when present but cause none when absent. Kano answers "what do customers actually value?" and is best used during discovery. A request can have hundreds of votes and still be a basic expectation customers will not thank you for — or a low-vote delighter worth building for differentiation. Feed Kano classifications into your RICE Impact scores.
The frameworks are complementary. A common sequence: use Kano during discovery to understand what matters, MoSCoW to scope a release with stakeholders, and RICE to sequence the build order within it.
The value vs effort matrix
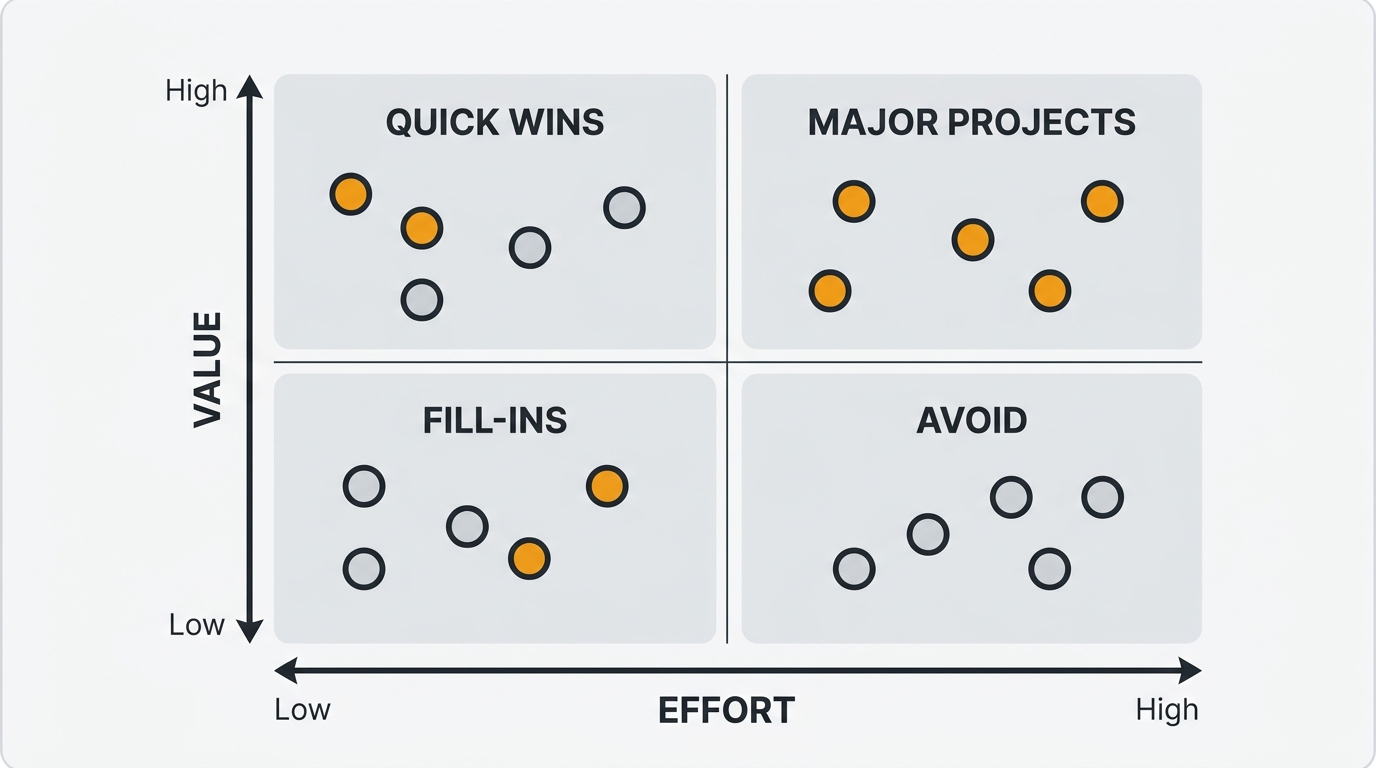
When you need a fast visual triage rather than a precise score, plot each request on a value vs effort matrix. Rate every request high or low on value and on effort, then place it in one of four quadrants:
- Quick Wins (high value, low effort): build these first. The return is highest here.
- Major Projects (high value, high effort): worth doing, but they need scoping and sequencing. Don't let them crowd out Quick Wins.
- Fill-Ins (low value, low effort): do these if you have spare capacity.
- Avoid (low value, high effort): say no, explicitly. Putting a request in the Avoid quadrant is more useful than leaving it ambiguous in the backlog.
The matrix surfaces trade-offs that are easy to miss when you evaluate requests one at a time. A request that seems essential in isolation often looks like poor value next to three alternatives that deliver comparable benefit for a fraction of the effort. When too many requests cluster in the same quadrant, the 2x2 has run out of resolution — that is your signal to move to weighted scoring or RICE. The prioritization matrix template covers both the 2x2 and the weighted version in detail.
Weight by customer value and revenue
This is the step that separates prioritization that grows the business from prioritization that merely keeps the loudest users busy. Two requests with identical vote counts can have wildly different value depending on who is behind the votes.
Three adjustments matter most:
Revenue and plan tier. Attach a dollar figure to each request wherever you can. If a request is blocking renewal for two accounts worth $80,000 a year combined, that belongs in your value estimate even if only two people voted. Conversely, a request with three hundred free-tier votes and no path to revenue should be weighted down, not up.
Segment and strategic fit. A startup chasing acquisition might weight requests from prospects and trial users heavily. A product optimizing retention weights existing-customer requests. The right weighting reflects what your team is trying to accomplish this quarter, not a universal formula.
Account health. A request from a healthy, expanding account is different from the same request attached to an account that is one frustration away from churning. Competitive necessity is a special case here: some requests don't create value, they prevent the loss of it. If a competitor ships something your customers expect you to match, the cost of inaction is churn, not missed growth.
The hard part has never been the math — it is getting reliable, revenue-aware inputs. This is where most spreadsheets break down. A vote count in a spreadsheet does not know which votes came from a $50,000 account. Connecting demand signal to customer value is the difference between a prioritized list and a prioritized list that compounds.
How Quackback surfaces true demand
This is the gap Quackback is built to close. Three capabilities work together to surface real demand instead of the loudest demand.
Vote-on-behalf. When a customer mentions a request on a sales call, in a support ticket, or over email, your team logs a vote on their behalf and attaches the account. The silent majority — the customers who would never visit a public board — finally show up in the data. That directly counters the loud-minority and survivorship problems above.
Value-weighting. Because votes carry account context, you can weight demand by revenue and plan tier rather than treating every vote as equal. A request backed by three enterprise accounts and a request backed by thirty free users no longer look identical in your prioritization.
AI theme summaries. Quackback's AI groups related requests, detects duplicates, and summarizes the themes running through hundreds of comments, so a request fragmented across twelve differently-worded posts shows its true combined weight. AI is built in — duplicate detection, theme summaries, and ingestion from Slack and email.
The result: the requests that rise to the top reflect weighted, deduplicated demand from your whole customer base, not the subset that happens to be loud.
Turn a prioritized list into a roadmap
A ranked list is not a roadmap. The final step is converting your scored, weighted requests into a sequence your team and your customers can act on.
Group by theme, not just score. Several individual requests often point at the same underlying need. Build the theme, not each request in isolation. AI theme summaries make these clusters obvious.
Sequence for dependencies. Scoring frameworks rank requests independently and ignore dependencies. If a high-scoring request depends on lower-scoring foundational work, the foundational work moves up regardless of its raw score. Resolve this when you build the roadmap, not during scoring.
Commit to horizons, not dates. Group work into Now, Next, and Later rather than promising specific dates you will miss. This keeps the roadmap honest as priorities shift.
Close the loop. When you ship a prioritized request, tell the people who asked for it. Linking requests to roadmap items and changelog entries turns prioritization into a visible feedback loop — customers see their input lead to shipped work, which drives more and better signal next cycle.
A public roadmap backed by weighted demand data also reduces a category of work that quietly drains product teams: answering "are you ever going to build X?" The answer is on the board, with its status, for everyone to see.
Try Quackback — open source with a managed cloud option. Start free. Get started | View on GitHub
Frequently asked questions
How do you prioritize feature requests with limited data?
Start with the strongest signal you have. Without vote data, use support ticket frequency and sales-call mentions as a demand proxy, and log votes on behalf of customers as they surface. Score with a value vs effort matrix first — it tolerates rough estimates better than RICE.
Should the most-voted feature always be built first?
No. Vote counts measure popularity, not value. The most-voted request often reflects your most online users rather than your most valuable customers, and ignores churned users who never voted. Weight votes by revenue, plan tier, and strategy fit before deciding build order.
What is the best framework for prioritizing feature requests?
There is no single best framework. Use RICE for a defensible numeric ranking across a large backlog, MoSCoW to scope a specific release with stakeholders, and the Kano model during discovery to understand how requests affect satisfaction. Most teams combine them.
How do you say no to a feature request?
Make the decision explicit and explain the trade-off. An explicit "won't have this release" bucket, as in MoSCoW, communicates the decision clearly. Tell the requester what you prioritized instead and why. A documented "no" on a public roadmap is better than silence, which reads as a maybe.
How often should you re-prioritize feature requests?
Re-prioritize at the start of each planning cycle, typically quarterly. Between cycles, revisit individual requests when significant new signal arrives — a spike in votes, a major account tying a renewal to a request, or a strategic shift in what counts as high value. Avoid re-scoring everything weekly.
Authored by James Morton
Founder of Quackback. Building open-source feedback tools.
Try Quackback
The open-source feedback platform. Boards, voting, and roadmaps.
Get startedStar on GitHub132